Relict
Reproducible Environmental DNA Analysis Platform with Conservation-Grade Provenance


Overview
Relict is an open-source environmental DNA analysis platform that turns raw FASTQ sequencing reads into publication-ready biodiversity data - ASVs, seven-rank taxonomy, alpha-diversity indices, and IUCN Red List conservation status - in a single automated run. Built for ecologists, citizen scientists, and conservation researchers who refuse to stitch together ten bash scripts and a spreadsheet. Every number is computed by real, peer-reviewed bioinformatics tools. No mock data. No fabricated metrics. Ever.
Not publicly deployed.
Book a 20-minute private walkthrough and I will run the whole system end-to-end: architecture, code path, live UI, and the edge cases that shaped it.
Book a private demoThe Problem
The eDNA field is mature in theory and broken in practice. Researchers burn weeks gluing QIIME2, R, and Excel together; conservation status is looked up species-by-species by hand; provenance - the exact tool versions, reference DB hashes, and parameters that produced a result - is almost never captured, making two-thirds of published eDNA findings irreproducible. Existing platforms either hide the pipeline behind a paywall or skip the conservation layer entirely. Small research groups end up publishing without GBIF-compliant metadata and their samples never make it into the global biodiversity record.
The Solution
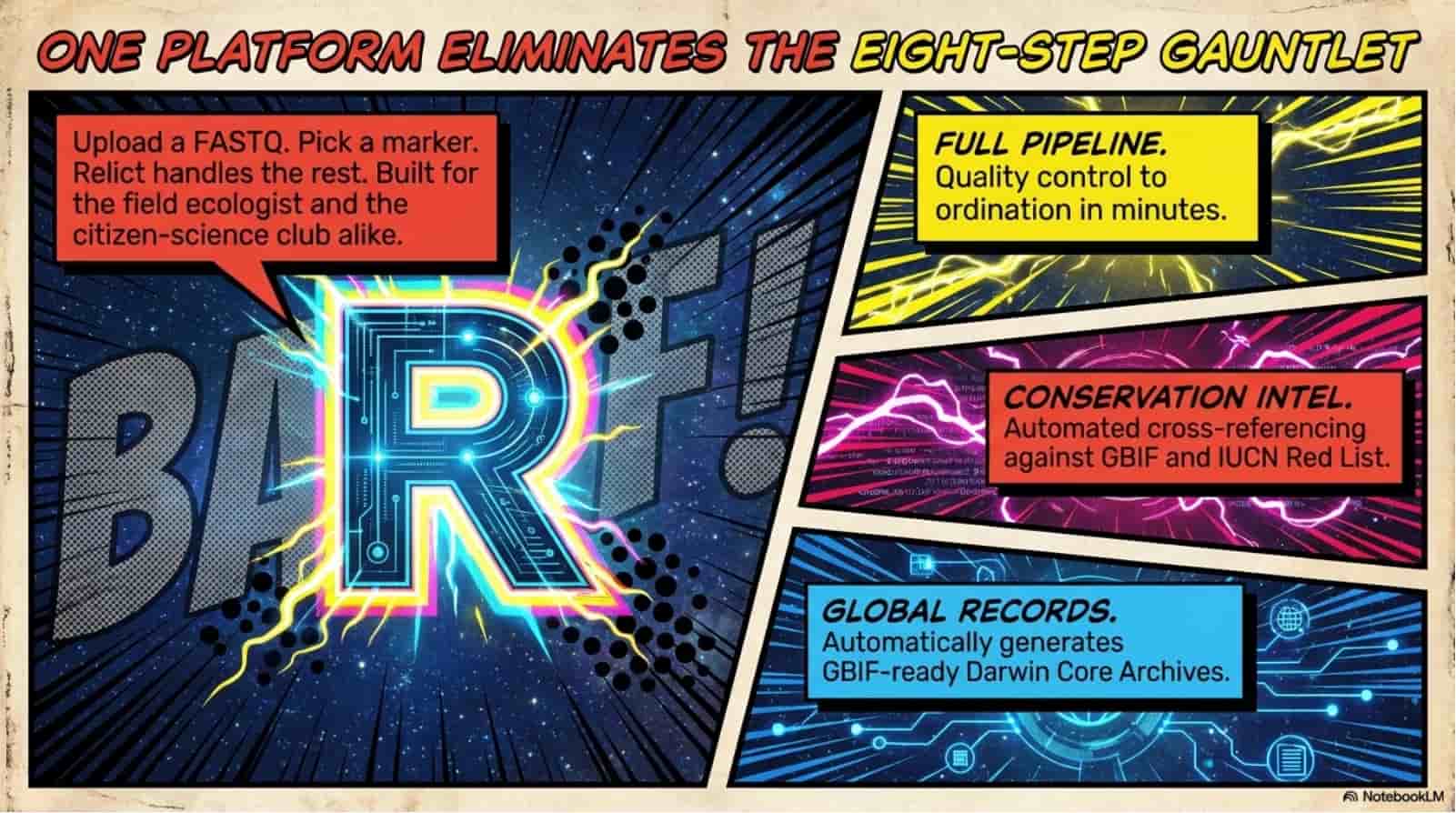
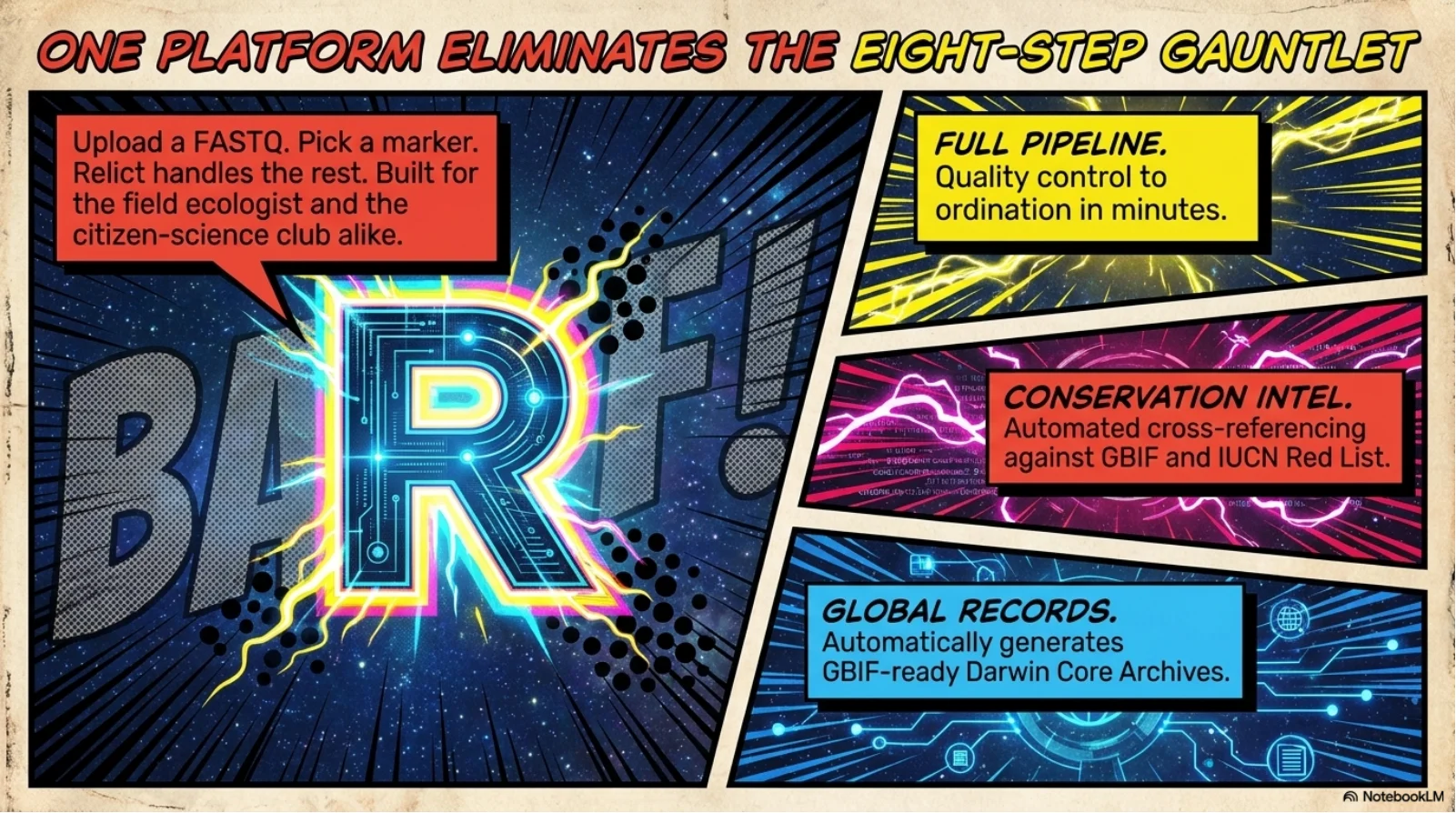
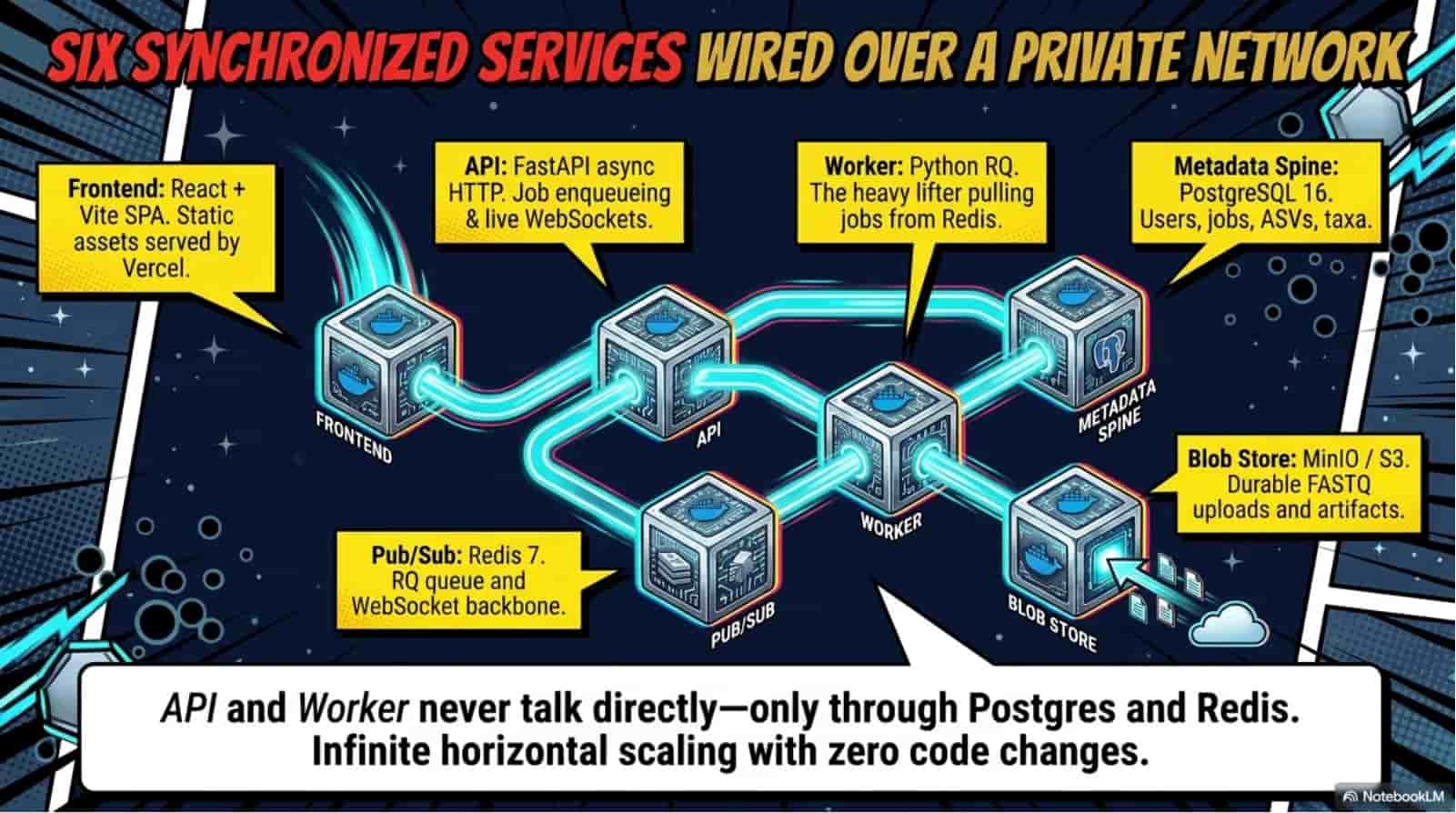
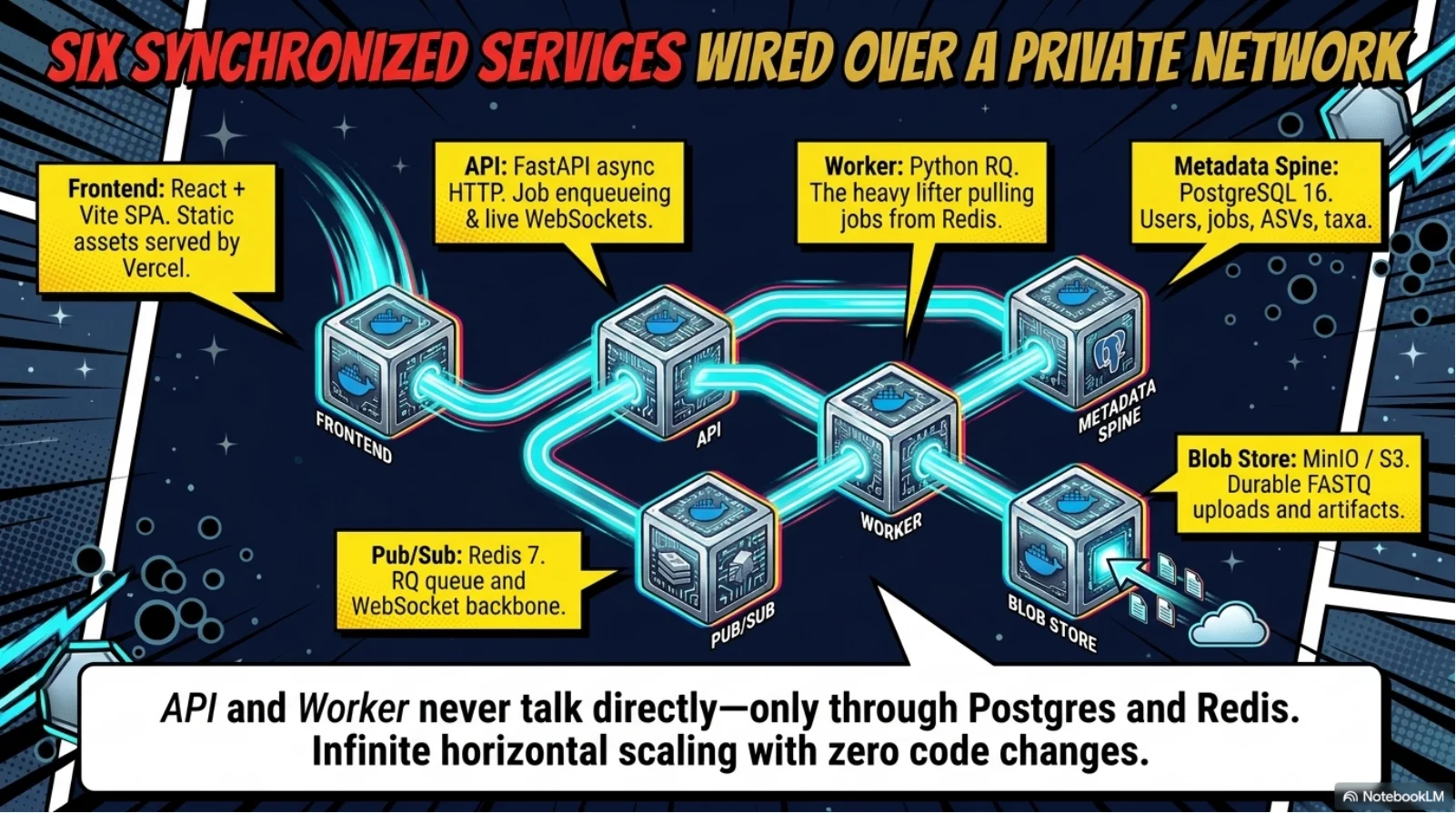
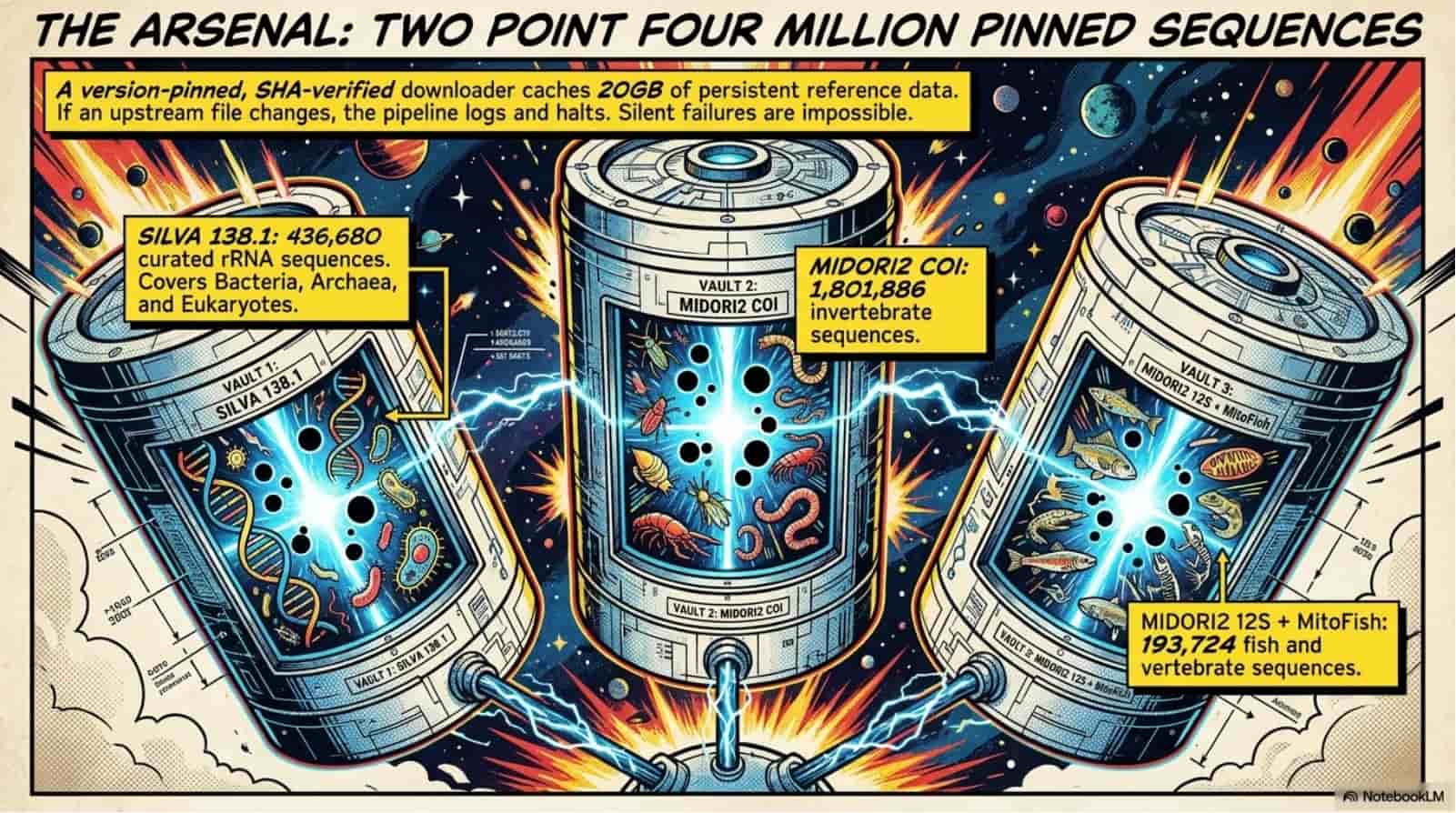
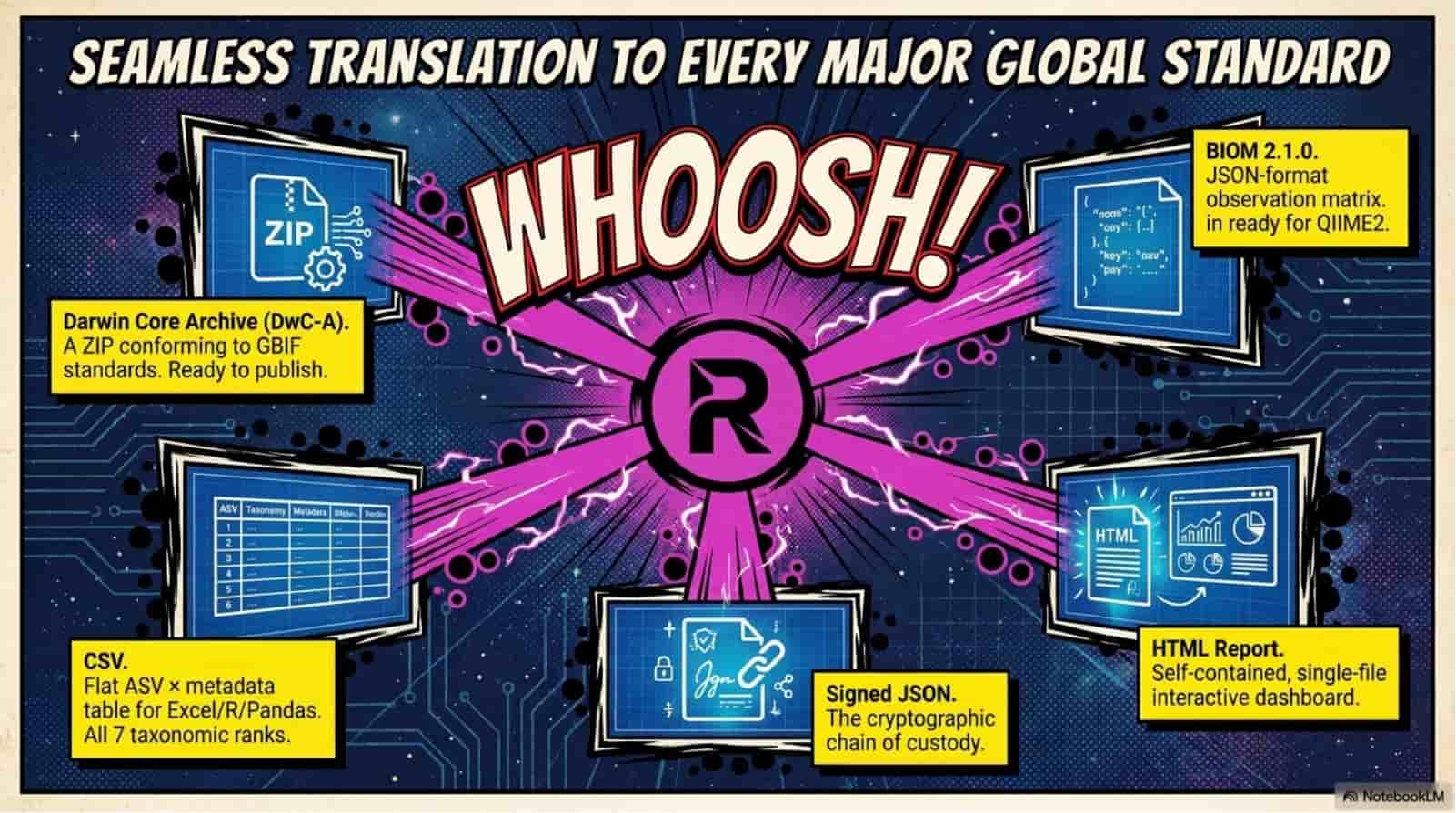
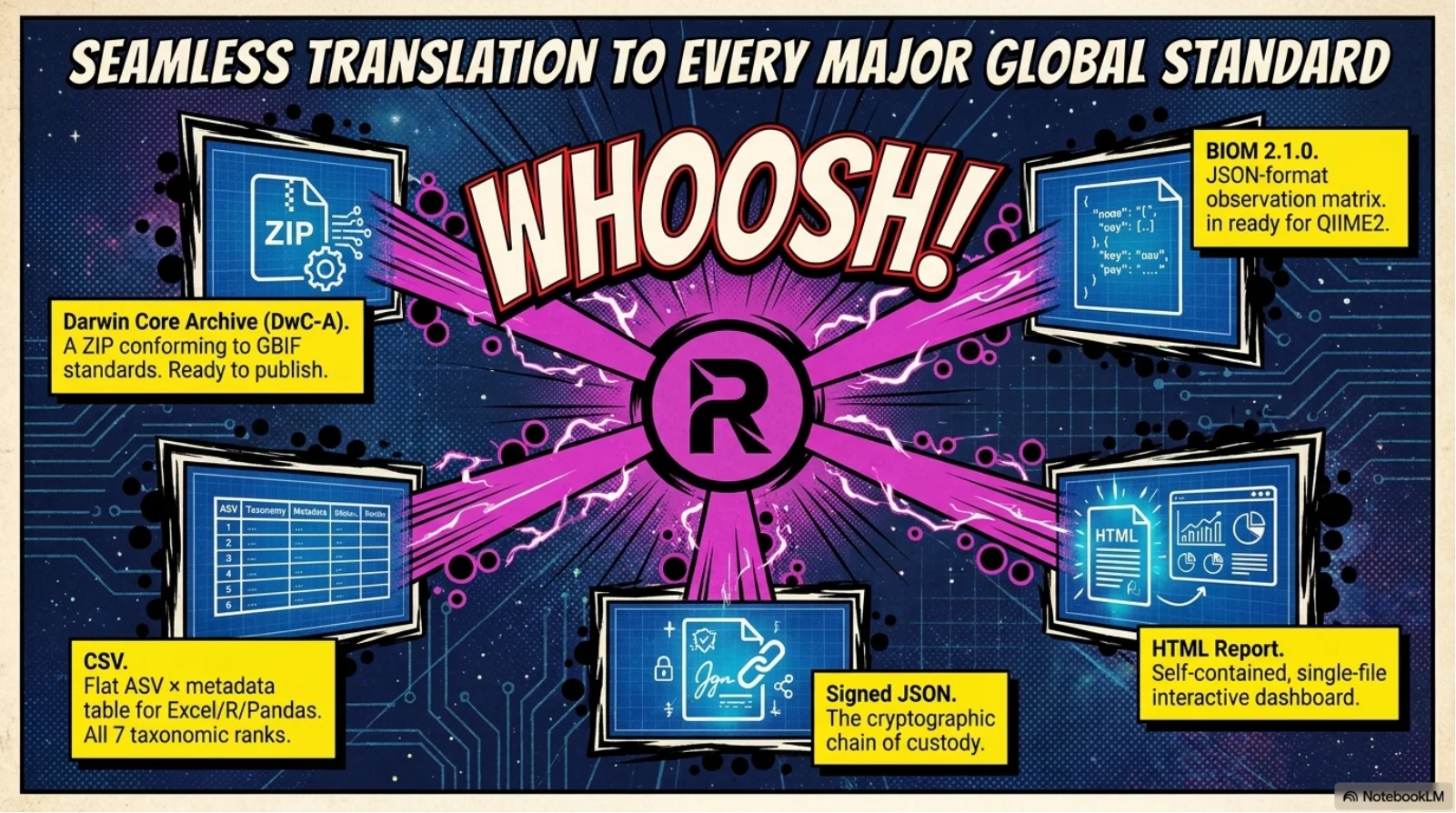
Relict collapses the eight-stage eDNA workflow into one async FastAPI pipeline: upload a FASTQ, watch eight stages stream progress over a live WebSocket, download a Darwin Core Archive that GBIF accepts without a single manual edit. Under the hood it wires fastp, vsearch UNOISE3, and scikit-bio to a PostgreSQL metadata spine and a signed SHA-256 provenance manifest that pins every tool version, every reference database, every parameter. The 2.4-million-sequence reference stack (SILVA 138.1 + MIDORI2 GB269 + MitoFish) lives on a mounted disk so taxonomy assignment runs in seconds, not hours. Reproducibility is not a doc page - it is cryptographically enforced.
Project Walkthrough
Agent Architecture
Sample Ingestion & Quality Control Engine
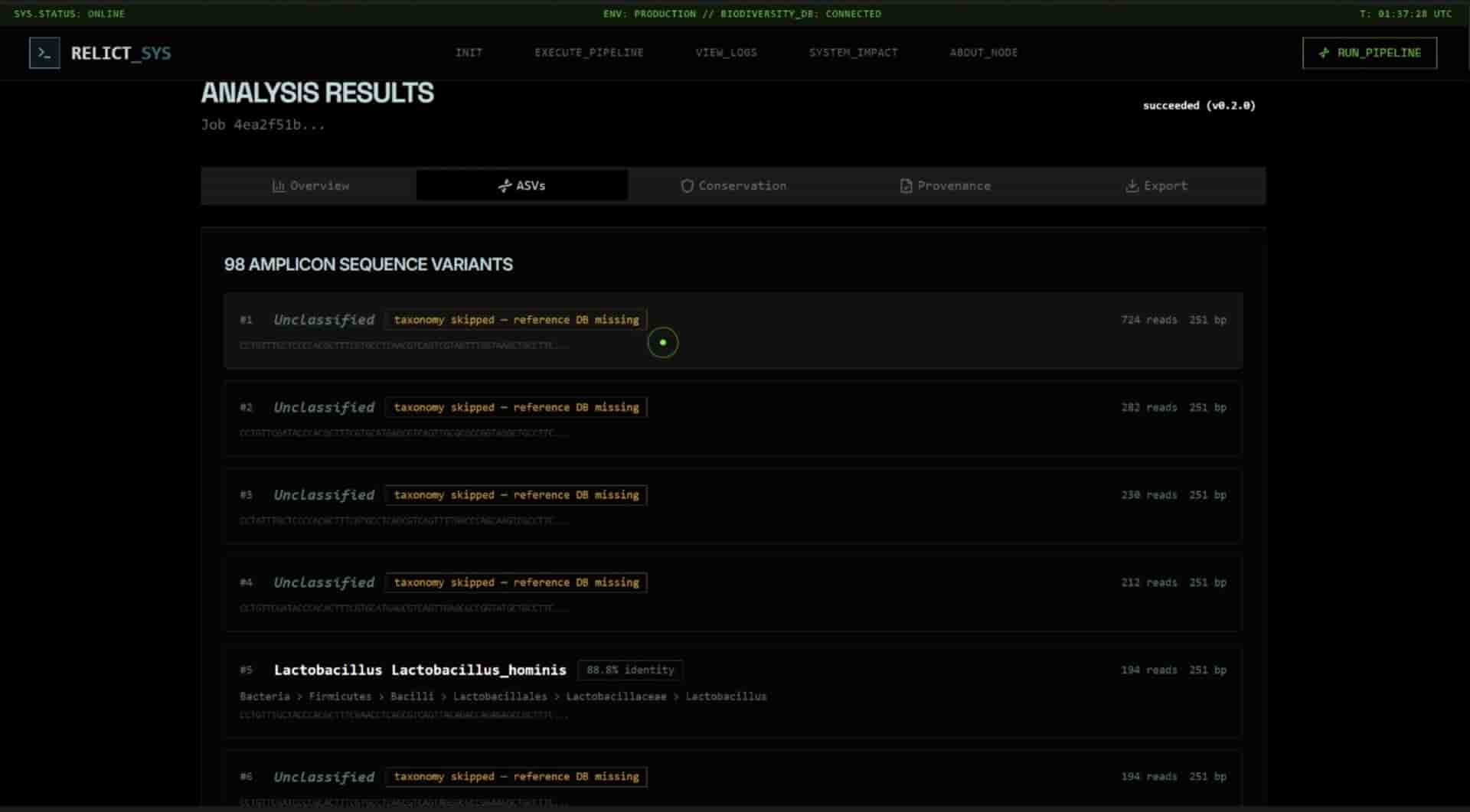
ASV Discovery Engine
Taxonomic Classification Engine
Conservation Intelligence Engine
Provenance, Diversity & Export Engine
System Architecture
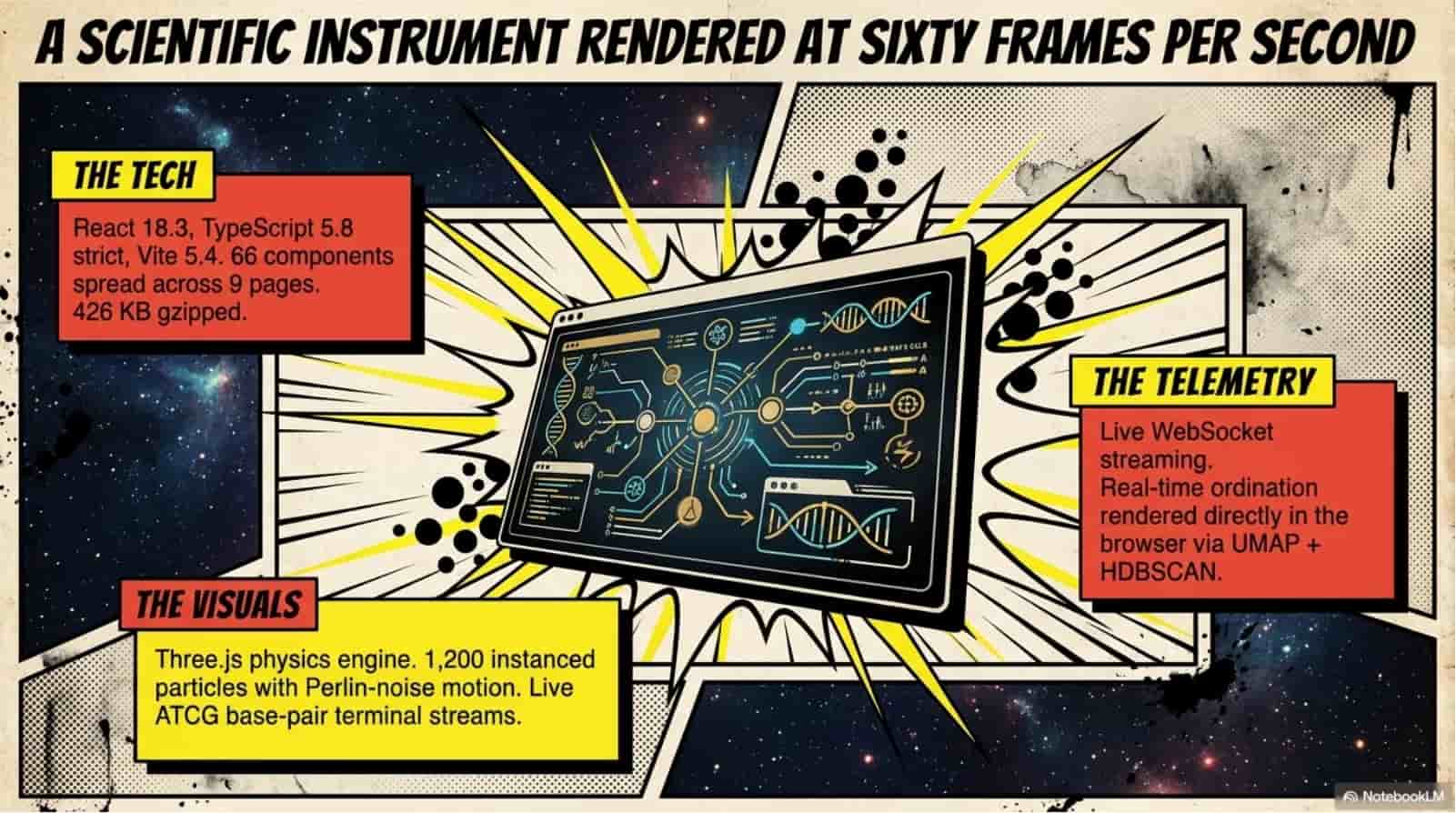
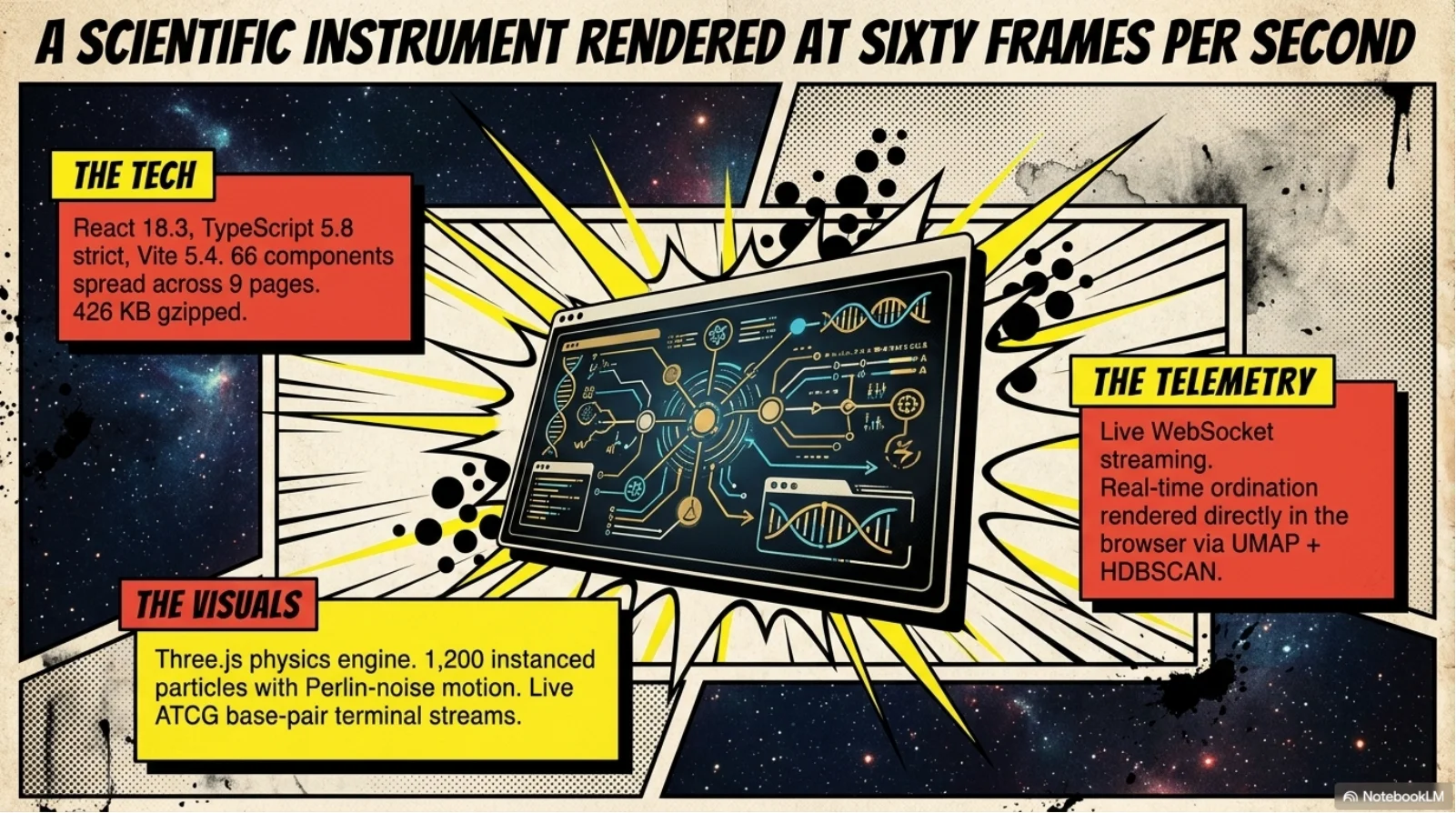
Technology Stack
client
- React 18.3
- TypeScript 5.8
- Vite 5.4
- Tailwind + shadcn/ui (66 components)
- Three.js / @react-three/fiber
- React Query, React Router v6, Framer Motion
- WebSocket live telemetry
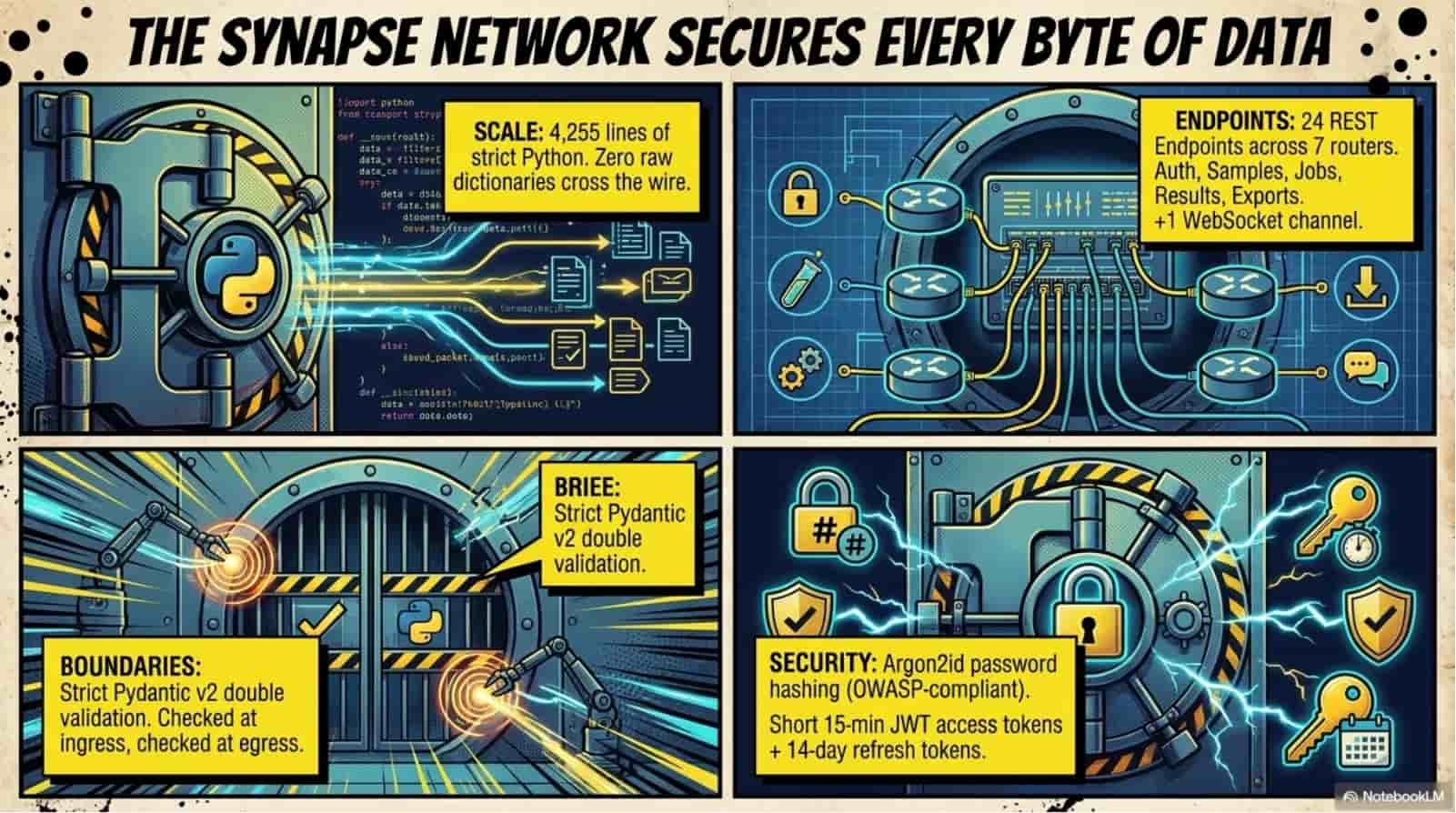
server
- Python 3.11 + FastAPI + Uvicorn
- 24 REST endpoints + 1 WebSocket channel
- SQLAlchemy 2.0 async + Alembic
- PostgreSQL 16 (9 tables, 110+ columns)
- Redis 7 (RQ queue + pub/sub)
- Argon2id + JWT access/refresh rotation
- structlog with request-ID propagation
bioinformatics
- fastp 0.24.0 (QC + adapter trim)
- vsearch 2.28.1 (dereplication, UNOISE3, global alignment)
- cutadapt 4.9 (primer trimming)
- scikit-bio 0.6.2 (alpha-diversity)
- umap-learn 0.5.7 + hdbscan 0.8.40
- biopython 1.84, biom-format 2.1.16
data
- SILVA 138.1 SSU NR99 (436,680 sequences)
- MIDORI2 GB269 COI (1.8M sequences)
- MIDORI2 12S (193,724 sequences)
- MitoFish mitogenomes
- GBIF Backbone + Occurrence API
- IUCN Red List v3 API
- S3-compatible blob storage (MinIO / R2 / S3)
- Docker Compose + Render Blueprint
Key Features
Eight-stage end-to-end pipeline - FASTQ in, GBIF-ready Darwin Core Archive out, zero manual steps.
Cryptographically signed provenance - every run emits a SHA-256-sealed manifest pinning tool versions, reference DB hashes, and parameters, so any result is byte-reproducible.
Integrated conservation layer - automatic IUCN Red List and GBIF cross-reference flags endangered and invasive species the moment they're detected.
Six amplicon markers, 2.4 million reference sequences - 16S V4, 12S MiFish, COI Leray, 18S V9, rbcL, ITS2, all version-pinned and SHA-verified.
Real-time WebSocket telemetry - the browser streams per-stage progress, read counts, and timing events as the worker executes. No polling, no "still working" spinner.
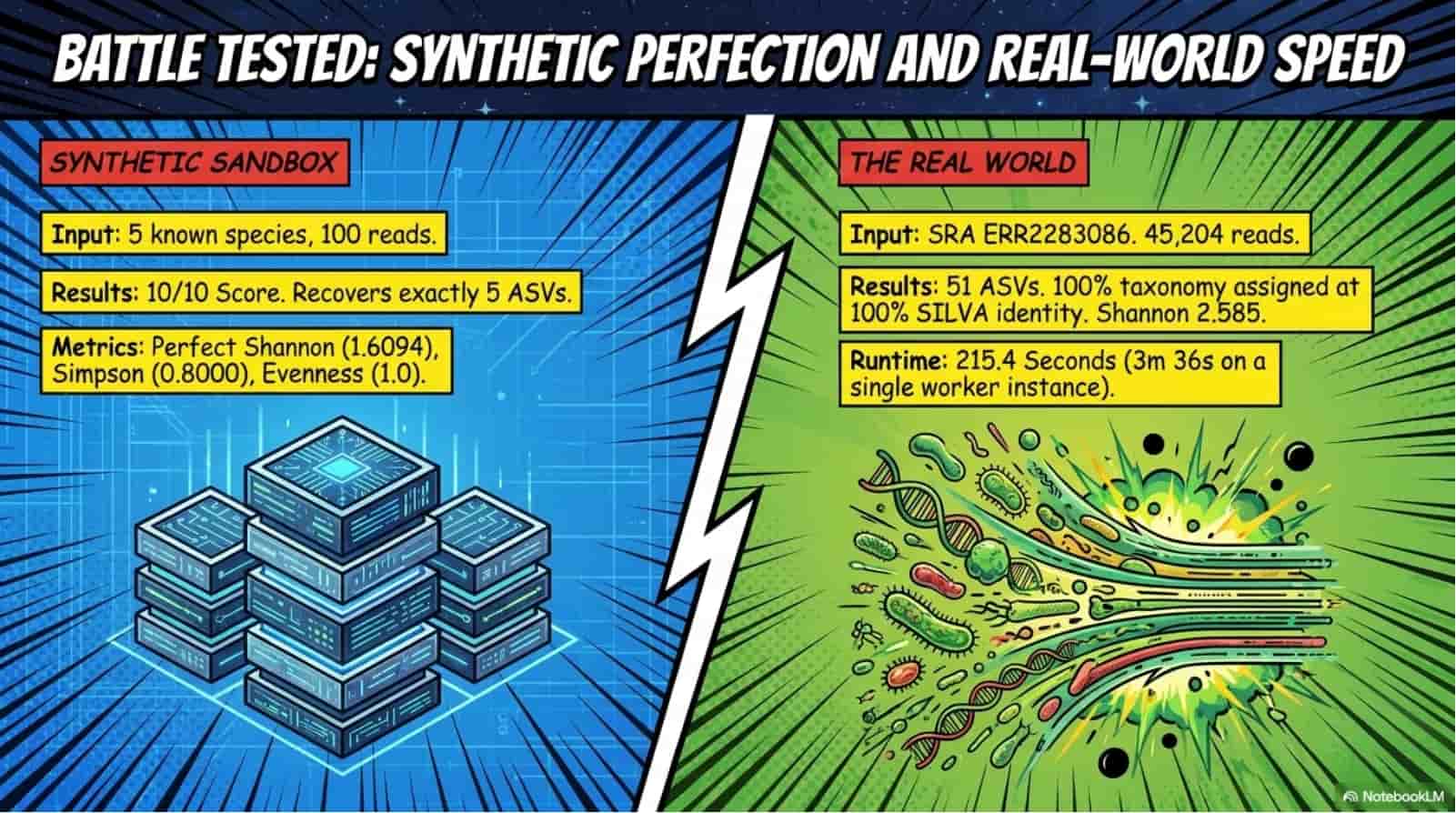
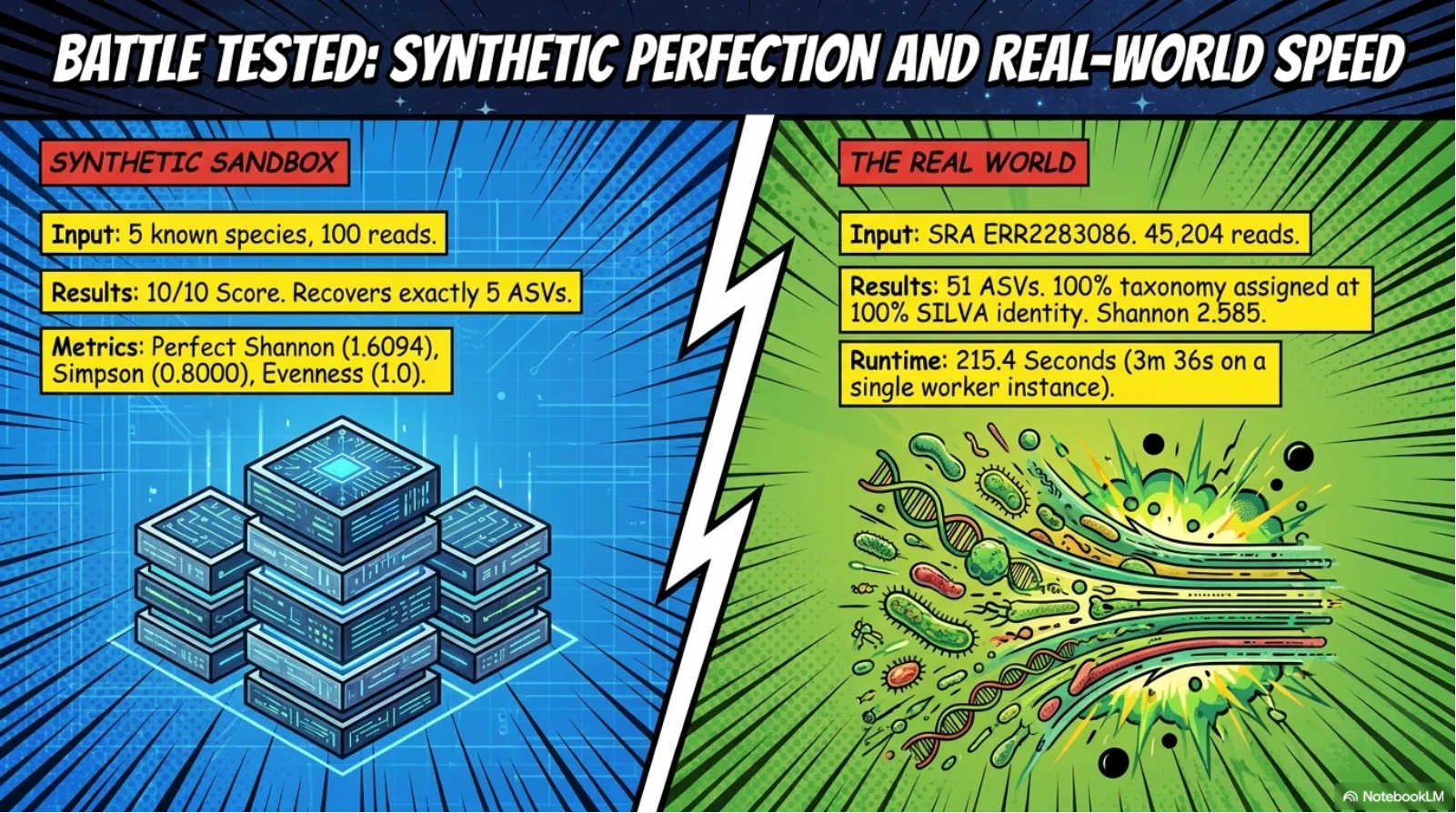
Publication-grade validation - 10/10 on synthetic mock community; 51 ASVs at 100% taxonomy assignment from a 45,204-read real SRA dataset in 3.6 minutes; research paper drafted for Methods in Ecology and Evolution.
Screenshots
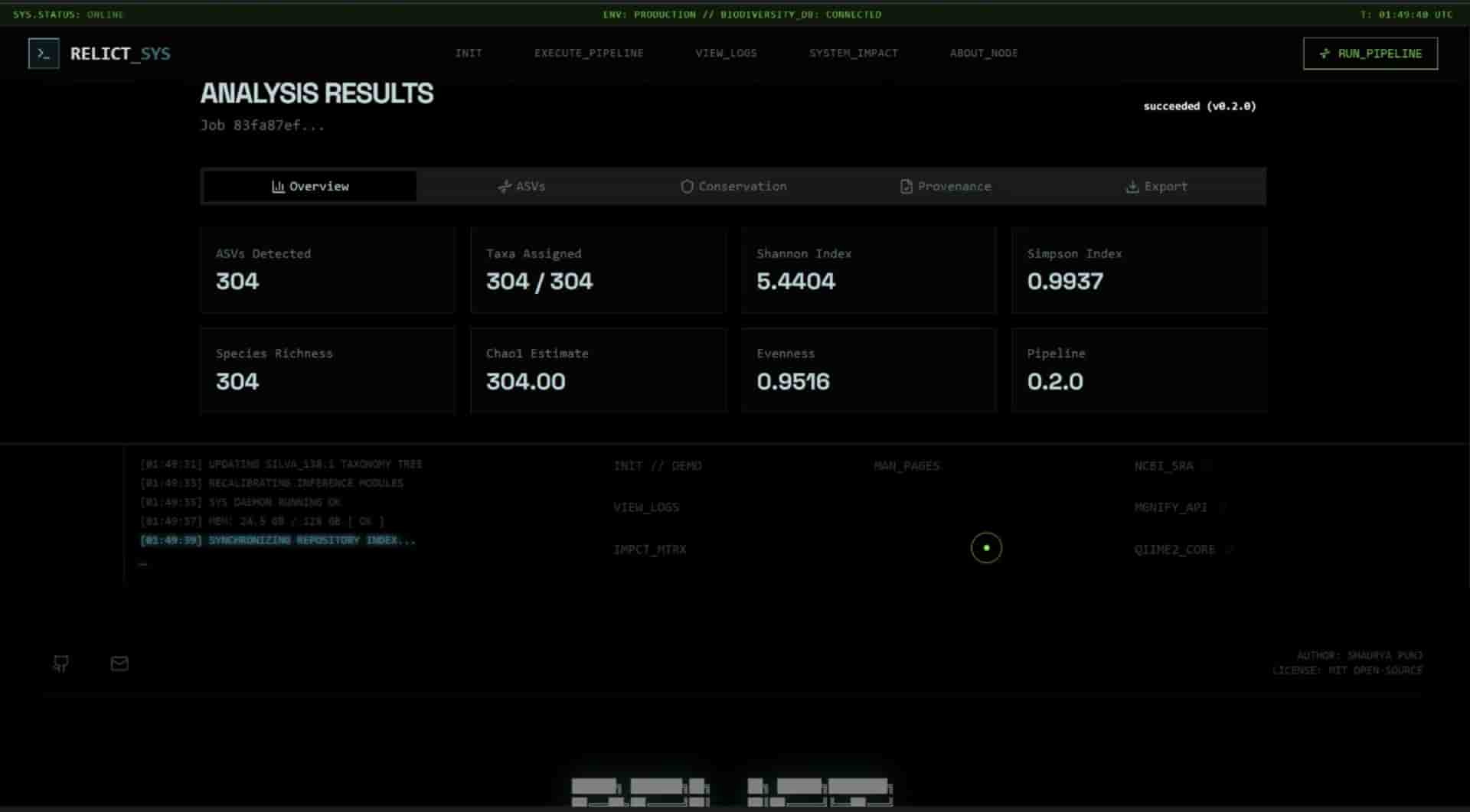
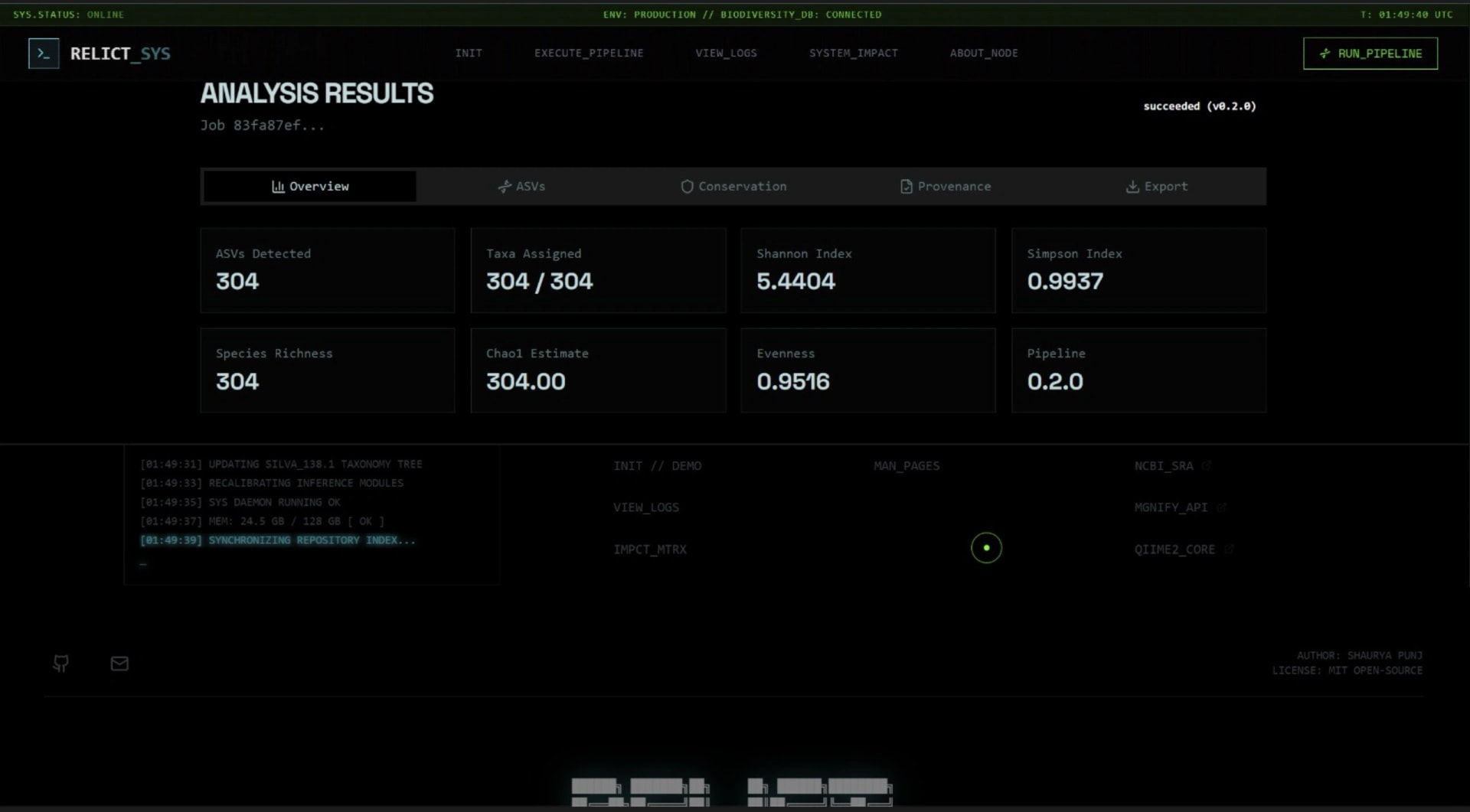
Project Presentation
15 slides
Design rationale, six-service architecture, the eight-stage eDNA pipeline, conservation cross-referencing, benchmarks, and the research publication track for Relict.
Download deck PDF